The Uncanny Valley
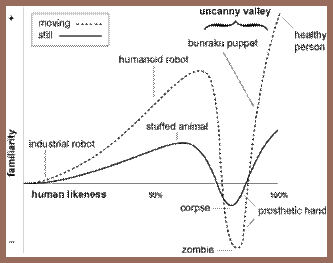
Forty years ago, Masahiro Mori presented his novel view on the perception of humanoid simulacra in a three page article in the Japanese magazine, Energy. This small piece contained no empirical data but it has colored the discourse in robotic-human interactions to the present day with its observations and insights. Access in the West to the notions Mori introduced in this publication has come almost entirely from a translation by Karl MacDorman and Takashi Minato.
The two major ideas were contained in a single figure that displayed two functions, each a plot of a bipolar measure of familiarity against the percentage of human likeness. A version of this graph, adapted from the translation, is presented above. One plot was for evaluation of representations that moved while the other was for those that were static. Both measures applied to three-dimensional physical objects. Each plot displayed a monotonic increase in perceived familiarity as human likeness increased from the origin, the point which marked objects that displayed an absence of human likeness and therefore induced no familiarity, to about 75% of complete likeness, a point where each plot displayed a local peak in familiarity at approximately 70% of its maximum. Beyond these local peaks, the subjective measure of familiarity in both plots rapidly decreased and became negative, with moving representations decreasing more than static ones. These values of negative familiarity were interpreted as inducing a feeling of strangeness in the observer. As human likeness increased further, the curves bottomed out for objects possessing a little over 80% of complete human likeness and again rose to assume positive values very near the end of the likeness range. Both curves achieved their respective familiarity maxima at the end of the range at 100% human likeness. It should be understood that these numbers are approximations taken in turn from what is likely a very approximate graph. Detailed data phrenology on these conceptual constructs is clearly unwarranted. Nonetheless, the great impact of this paper is that it made people aware that the region of negative familiarity, or strangeness, which occurred at high levels of human likeness just short of perfection. This is a region that has come to be known as The Uncanny Valley and constitutes the major impediment to the successful implementation of simulated human beings.
The second of Mori’s conjectures revolved around the relative ratings for moving and static three-dimensional representations. Mori proposed that moving simulacra were endowed with familiarity at a greater rate as their human likeness increased, succumbed to lower ratings in the Uncanny Valley, and achieved greater familiarity maxima as they reached complete human likeness than did non-animated humanoid representations of equivalent human likeness. Empirically, the performance of moving 3D objects were able to reach very high levels of human likeness and were able to generate appreciable amounts of familiarity (as with the bunraku puppets) even though the ratings of both human likeness and the familiarity that the same objects engendered when static were usually appreciably lower.
Mori’s simple thesis has stimulated no end of discussion. Some contention has arisen over questions concerning the correctness of the translation. Issue was taken with the meaning of familiarity and the quantification of human likeness. It might be expected that all instances of 100% human likeness should accrue the same maximum familiarity, else what does 100% mean? Alternatively, 100% human likeness could constitute an ideal or perhaps a norm. The plot of actual humans could take the form of a cloud of values at the right end of the graph – the imperfect matches to a personal archetype degraded due to the ravaged aesthetics of age and disease or enhanced by the degree of shared personal history or cultural heritage.
In addition to the semantics, the application of these ideas to two-dimensional images might also be questioned. Is it possible for the notions initially applied to physical 3D objects be carried over to planar representations, a format yet further removed from physically present human beings? The one thing that is certain to me in this debate is that whatever the properties that define the essence of humanness in humanoid representations, they remain to be implemented in their entirety for, according to almost all critical analysis, no artificial construction attempted to date in the cinema with simulated human actors or in a physical 3D format such as humanoid robotics has yet to approach the appearance of humans without falling into the Uncanny Valley.
Although Mori’s interpretation of the factors that influence our perceptions have been borne out at the box office by a long string of very expensive failures of animated movies that attempt to present photorealistic humans, his claims have been criticized for being too subjective and lacking in empirical validation. Recently, however, relevant studies have been appearing in fields as diverse as neurophysiology, visual psychophysics and cognition.
While earlier research found little correlation between mate preference judgments made with still and video images, Roberts and colleagues conducted an analysis of the effects of a range of presentation variables and found that there were significant interactions but that the perceived attractiveness of still images of faces were generally a good predictor of the usually greater attractiveness of moving representations. In another study, Looser and Wheatley morphed facial images between humans and mannequins and found that the point where subjects reported perceptions of the presence of ‘life’ and ‘mind’ were consistently very near the human end of the transformation. They also reported that of all the facial features the eyes contributed more to the presence of animacy than anything else.
Evidence is increasing that the human brain provides privileged access to a range of specialized mechanisms dedicated to facial image processing. Atkinson and Adolphs presented an interactive model where different cortical areas combine in different ways to support functions such as facial identification, emotional state and trustworthiness. The details are just beginning to be worked out but the parallels to Mori’s familiarity-likeness schema appear to be strong. Evidence now exists that observers do consistently report stronger responses to moving representations. Future analysis of observer data to compare correlation strength of still and moving faces with specific features and poses should provide a better interpretation of familiarity. Similarly, discovery of the effects such as eye quality have on inducing the perception of animacy should help tease out what causes some feature combinations to become ‘uncanny’.
Allow me to insert a piece of relevant contention here before closing. From the translation of the original article, it appears that Mori was concerned mostly with a real life test of human perception – comparing physical 3D objects to physical 3D objects. We have moved away from that original interpretation in the intervening decades and, in doing so, have changed the meaning of his evaluation. Motivated by the requirements inherent in computer and cinematic imaging applications, the discourse on humanoid appearance has shifted from characterizing 3D objects, an evaluation reflecting Mori’s interest in integrating robots into society, to the characterization of the 2D presentation of moving or static 3D object representations. This shift in evaluation reflects the increasing importance of inserting the human form into the devices we depend on for work and entertainment.
Having substantially altered the task, we need to address the differences between evaluating physical objects and evaluating images of physical or of simulated objects. These differences impact our evaluations no matter how familiar we have become with the conceit of considering various moving luminance and chromatic reflectance patterns of three-dimensional objects projected onto a planar surface as ‘real’. While it should be theoretically possible to digitally represent a human being with all the detail that is accessible to the human visual system, sufficient resources are rarely brought to the task. To make matters worse, market forces currently tend to push display design in the opposite direction. Devices are becoming thinner and lighter while supporting more and brighter pixels on a smaller energy budget. In practice, these demands on the hardware introduce both physical and cognitive complications into the evaluation. There is no simple way to implement a ‘Memorex’ test for the visual comparisons of human likeness that affords a device-independent evaluation of the images – a test that is derived from the content alone. This limitation holds even if the test is further reduced to one of monocular viewing. The net result of these device shortcomings is to alter the interpretation our visual system gives to the flawed simulacra by increasing an already disaffectionate tone.
Today, digital representations are becoming universal. The digitization process with all its degrees of freedom provided by the conversion parameters that control spatial, intensive and chromatic quantization acts to filter the presentation of both humans and humanoids. The evaluation of these digital representations on a display monitor presents additional intrusions in any test due to the transfer characteristics of the viewing device. Even if we attempt to return to Mori’s original intent through the construction of simulated 3D objects with two 2D planar images presented separately to each eye, we will still be at the mercy of the medium, perhaps only more so. Stereopsis is a very finicky modality. The extent to which these transformations mask or enhance representational flaws is still an open question, especially so for 3D CGI. While we may be conditioned to invoke a degree of suspension for some of our existing perceptual mechanisms in the darkness of a movie theater, nonetheless, these assays are intrinsic to our physiology and remain in place.
All this technical detail aside, structural flaws in many of these representations will still compel a feeling of unease for even the most realistic of the high-end creations. While I believe it can be argued that no animated (moving) humanoid representation has spanned the Uncanny Valley and approached the ideal of human appearance without incurring appreciable strangeness, the status of static image representations is a good bit fuzzier. I believe that the claim of inadequacy also still holds for viewing motionless physical 3D humanoid objects. Even if they contain an accurate simulation of the patterns of surface relief and the distribution subsurface chromophores, the distribution and maintenance of appropriate fluids on the skin, eyes, and oral and nasal cavities and their contribution to specular reflectance sets a particularly high bar for any physical implementation.
With respect to 3D CGI, it can be argued that exiting the Uncanny Valley often displays a gradation in the success that can be appropriately ascribed. It might be considered to be a success if motion capture is applied to an individual and images of the person’s skin are warped and texture-mapped on a sufficiently detailed and pliant rigging which can be animated with appropriate articulation guided by the captured patterns of movement. However, this representation is perhaps more of a transformation than a creation.
Another level of success might be to mix and match different collections of the salient anatomical features – eyes, lips, nose – and put together a patchwork of these individually optimized structures. This representation evinces some creation but often lacks the glue the produces a vital whole. It can be argued that the ultimate gold standard for crossing beyond the Uncanny Valley is to possess a parametric characterization of all the required body details so as to be able to assemble a novel representation from whole cloth using the most basic physiological and optical properties integrated into a realistic amalgam. Such an organization would need to go further than a comprehensive collection of anatomic detail and would allow the modulation of that detail with appropriate site-specific associations and global interrelationships.
Although there are several projects that are fast closing in this goal (e.g., The Digital Emily Project), achieving it will not likely be an indisputable event. Is success to be determined by one observer, even a noted one, not being able to recognize a simulation under one set of conditions? Probably not. It will likely be more of a growing consensus that emerges over time due to a collection of experiments and observations.
Finally, there is no shortage of static 2D photorealistic artistic renditions of humans that would fool my eyes, or those of any observer, on a regular basis when the judgment is one of the photographic accuracy of an image of a purported human being. If an artist can match the appearance of a photographic image of a human to the extent that the difference cannot be discerned, does that constitute crossing the Uncanny Valley? I think not.
Why not? The process is still insufficient because these representations are like the Ames room. Technically, they meet the required criteria of perceptual equivalence, but the appearance is obtained in such a constrained manner that there is no functionality left in their implementation. In general, these realistic artistic creations are not the result of an understanding of the interaction of tissue and optics. Rather, they are largely the result of a process of duplicating images of real humans by humans. To accomplish this, the artist repeatedly applies the same internal assessment mechanism we all possess, the same mechanism that produces the Uncanny Valley, to adjust the flawed details of the design until a satisfactory result is achieved.
What about applying a more stringent criterion? In Mori’s original evaluation, an observer was free to move about a static 3D simulation. Consider simultaneous comparisons of real and artificial representations – video capture of a static live person versus a simulation of the same individual. Even if this experiment doesn’t gain purchase in the community as an appropriate hurdle, it should be of interest to compare two such representations and to note where the differences occur.
The same comparison test could be extended to the evaluation of moving simulations. The difficulty with defining such a test, however, is in finding a way to characterize the video of a real person in a way that instructs the creation of the simulation without simply creating a cloning mechanism. While such ‘copying’ is common in still image creation, advances in motion capture raise significant questions there as well. How much credit should accrue to simulation efforts that draw significant information directly from the representation of an actual human being? Not so much.
Perhaps an appropriate extension of Mori’s 3D notions to the CGI world would be to require that the source of these static 2D representations be a 3D model coupled with a generative mechanism. A parameterized generic model that is not derived from the reflectance of a specific human being but can be tuned to produce different 2D projections for evaluation. This 3D CGI model should be capable of photorealistically accommodating a wide range of illumination configurations as well as incorporating a variety of the possible forms of light-tissue interaction. The model needn’t be articulated, or even deformable. It just would need to interact realistically with the incident light as viewed from different observation points and do so at least down to a level of detail that will allow normal human vision to warrant the representation as indistinguishable from digital images of actual humans.
With this interim standard, it should be possible to address some significant 3D issues while putting off the requirement for incorporating the harder tasks of realistic articulation, deformation, stereopsis and display until the day those algorithms and devices are ready for prime time. That day should not be too far off, either. The technology and the techniques to produce 3D representations are moving forward apace as is the ability to create accurate and detailed simulations of the human form. These representations are appearing more commonly on computers, cinema projection systems and even mobile devices. Whatever stumbling blocks still remain, it is clear that the transition will soon be upon us and we go from where successes are rare to where such simulations can be created with an off-the-shelf toolkit.
(Original source: Masahiro Mori Uncanny Valley (Bukimi no tani) Energy, Vol. 7, No. 4, pp.33-35, 1970. Mori founded the Jizai Kenkyujo (Mukta Research Institute) to support future work in this area.)
Brian C. Madden